When I made the first version of the Plain Vanilla website, there were things that I would have liked to spend more time on, but that I felt didn't belong in a Good Enough™ version of the site. One of those things was defending against Cross-Site Scripting (XSS).
XSS is still in the OWASP Top Ten of security issues, but it's no longer as prevalent as it used to be. Frameworks have built in a lot of defenses, and when using their templating systems you have to go out of your way to inject code into the generated HTML. When eschewing frameworks we're reduced to standard templating in our web components, and those offer no defense against XSS.
Because of this, in the original site the Passing Data example on the Components page had an undocumented XSS bug. The name field could have scripts injected into it. I felt ambivalent about leaving that bug in. On the one hand, the code was very compact and neat by leaving it in. On the other hand it made that code a bad example that shouldn't be copied. I ended up choosing to leave it as-is because an example doesn't have to be production-grade and generating properly encoded HTML was not the point of that specific example. It's time however to circle back to that XSS bug and figure out how it would have been solved in a clean and readable way, if Santa really did want to bring his List application to production-level quality.
The problem
The basic problem we need to solve is that vanilla web components end up having a lot of code that looks like this:
class MyComponent extends HTMLElement {
connectedCallback() {
const btn = `<button>${this.getAttribute('foo')}</button>`;
this.innerHTML = `
<header><h1>${this.getAttribute('bar')}</h1></header>
<article>
<p class="${this.getAttribute('baz')}">${this.getAttribute('xyzzy')}</p>
${btn}
</article>
`;
}
}
customElements.define('my-component', MyComponent);
If any of foo, bar, baz or xyzzy contain one of the dangerous HTML entities,
we risk seeing our component break, and worst-case risk seeing an attacker inject a malicious payload into the page.
Just as a reminder, those dangerous HTML entities are <, >, &, ' and ".
The fix, take one
A naive fix is creating a html-encoding function and using it consistently:
function htmlEncode(s) {
return s.replace(/[&<>'"]/g,
tag => ({
'&': '&',
'<': '<',
'>': '>',
"'": ''',
'"': '"'
}[tag]))
}
class MyComponent extends HTMLElement {
connectedCallback() {
const btn = `<button>${htmlEncode(this.getAttribute('foo'))}</button>`;
this.innerHTML = `
<header><h1>${htmlEncode(this.getAttribute('bar'))}</h1></header>
<article>
<p class="${htmlEncode(this.getAttribute('baz'))}">${htmlEncode(this.getAttribute('xyzzy'))}</p>
${btn}
</article>
`;
}
}
customElements.define('my-component', MyComponent);
While this does work to defend against XSS, it is verbose and ugly, not pleasant to type and not pleasant to read.
What really kills it though, is that it assumes attention to detail from us messy humans. We can never forget,
never ever, to put a htmlEncode() around each and every variable.
In the real world, that is somewhat unlikely.
What is needed is a solution that allows us to forget about entity encoding, by doing it automatically when we're templating. I drew inspiration from templating libraries that work in-browser and are based on tagged templates, like lit-html and htm. The quest was on to build the most minimalistic html templating function that encoded entities automatically.
The fix, take two
Ideally, the fixed example should look more like this:
import { html } from './html.js';
class MyComponent extends HTMLElement {
connectedCallback() {
const btn = html`<button>${this.getAttribute('foo')}</button>`;
this.innerHTML = html`
<header><h1>${this.getAttribute('bar')}</h1></header>
<article>
<p class="${this.getAttribute('baz')}">${this.getAttribute('xyzzy')}</p>
${btn}
</article>
`;
}
}
customElements.define('my-component', MyComponent);
The html`` tagged template function
would automatically encode entities, in a way that we don't even have to think about it.
Even when we nest generated HTML inside of another template, like with ${btn}, it should just magically work.
It would be so minimal as to disappear in the background, barely impacting readability, maybe even improving it.
You may be thinking that doing that correctly would involve an impressive amount of code. I must disappoint.
class Html extends String { }
/**
* tag a string as html not to be encoded
* @param {string} str
* @returns {string}
*/
export const htmlRaw = str => new Html(str);
/**
* entity encode a string as html
* @param {*} value The value to encode
* @returns {string}
*/
export const htmlEncode = (value) => {
// avoid double-encoding the same string
if (value instanceof Html) {
return value;
} else {
// https://stackoverflow.com/a/57448862/20980
return htmlRaw(
String(value).replace(/[&<>'"]/g,
tag => ({
'&': '&',
'<': '<',
'>': '>',
"'": ''',
'"': '"'
}[tag]))
);
}
}
/**
* html tagged template literal, auto-encodes entities
*/
export const html = (strings, ...values) =>
htmlRaw(String.raw({ raw: strings }, ...values.map(htmlEncode)));
Those couple dozen lines of code are all that is needed. Let's go through it from top to bottom.
class Html extends String { }- The Html class is used to mark strings as encoded, so that they won't be encoded again.
export const htmlRaw = str => new Html(str);- Case in point, the htmlRaw function does the marking.
export const htmlEncode = ...- The earlier htmlEncode function is still doing useful work, only this time it will mark the resulting string as HTML, and it won't double-encode.
export const html = ...- The tagged template function that binds it together.
A nice upside of the html template function is that the html-in-template-string Visual Studio Code extension can detect it automatically and will syntax highlight the templated HTML. This is what example 3 looked like after I made it:
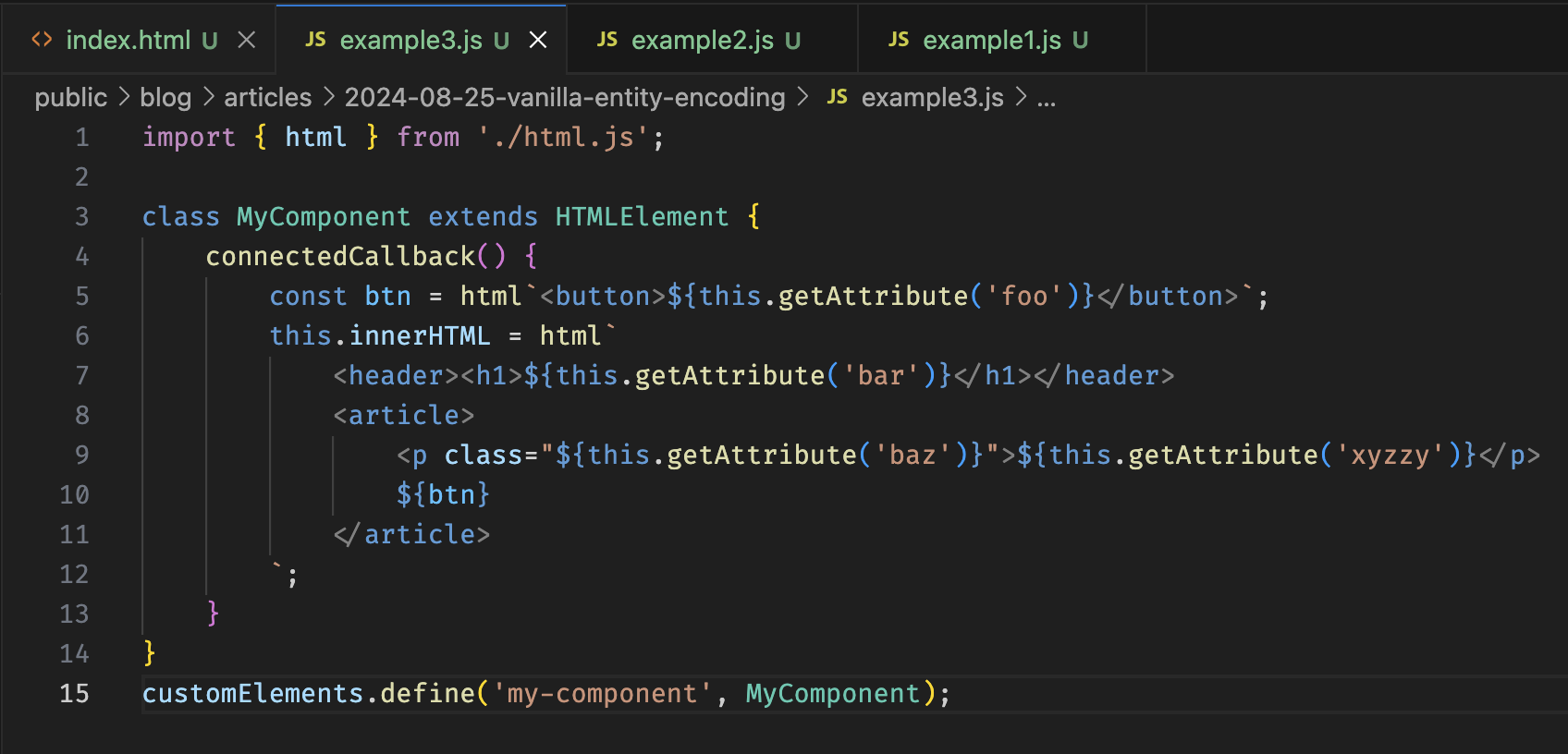
Granted, there's still a bunch of boilerplate here, and that getAttribute gets unwieldy.
But with this syntax highlighting enabled sometimes when I'm working on vanilla web components I forget it's not React and JSX, but just HTML and JS.
It's surprising how nice of a development experience web standards can be if you embrace them.
I decided to leave the XSS bug in the Passing Data example, but now the Applications page has an explanation about entity encoding documenting this html template function. I can only hope people that work their way through the tutorial make it that far. For your convenience I also put the HTML templating function in its own separate html-literal repo on Github.
]]>